 递归、搜索和回溯
递归、搜索和回溯
# 递归
递归就是自己调用自己
# 为什么用递归
本质:解决一个主问题时出现了一个相同的子问题,如此循环就可以使用递归,直到出现了无法分解的最小问题
# 怎么写递归
如何宏观看代递归过程:
- 不要在意递归的细节展开图
- 将递归函数当成一个黑盒
- 足够相信这个黑盒一定可以完成任务
- 先找到相同的子问题 --> 函数头的设计
- 关心某一个子问题如何解决 --> 函数体的设计
- 从最小子问题判断结束条件 --> 出口的设计
# 搜索
搜索分为两种:
- 深度优先搜索/深度优先遍历/dfs(递归、栈)
- 宽度优先搜索/宽度优先遍历/bfs(队列)
# 二叉树的深搜
深度优先遍历(DFS,全称为 Depth First Traversal),是我们树或者图这样的数据结构中常用的一种遍历算法。这个算法会尽可能深的搜索树或者图的分支,直到一条路径上的所有节点都被遍历完毕,然后再回溯到上一层,继续找一条路遍历。
在二叉树中,常见的深度优先遍历为:前序遍历、中序遍历以及后序遍历。因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历不仅容易理解而且代码很简洁,并且前中后序三种遍历的唯一区别就是访问根节点的时机不同,在做题的时候,选择一个适当的遍历顺序,对于算法的理解是非常有帮助的。
例题:验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。有效二叉搜索树定义如下:
- 节点的左子树只包含 严格小于 当前节点的数。
- 节点的右子树只包含 严格大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树
解答:根据定义,中序遍历一棵二叉搜索树的数组是升序的
class Solution {
public:
long long end = LONG_MIN;
// 中序遍历:
bool dfs(TreeNode* root) {
if (root == nullptr)
return true;
if(!dfs(root->left)) // 剪枝:左子树不是二叉搜索树,返回false
return false;
if(root->val <= end) // 不是升序?返回false
return false;
end = root->val;
return dfs(root->right); // 返回左子树是否为二叉搜索树
}
bool isValidBST(TreeNode* root) { return dfs(root); }
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 回溯与剪枝
- 回溯本质就是深搜,回溯 --> “恢复现场”
- 剪枝就是发现某种情况一定不行,直接除去情况,大多数的剪枝就是做一下判断
- 不管深搜、回溯还是剪枝,画出决策树,越详细越好,然后从全局变量和递归函数来设计代码
- 用全局变量、函数参数、函数引用参数来辅助:事实上,全局与引用参数类似,都是需要处理恢复现场的操作,而函数参数由函数帮助处理了。所以像数组这样的类型适合全局变量;单个类型适合参数
例题 1:二叉树的所有路径
给你一个二叉树的根节点 root ,按任意顺序 ,返回所有从根节点到叶子节点的路径。
- 输入:root = [1,2,3,null,5]
- 输出:["1->2->5","1->3"]
class Solution {
public:
vector<string> ans;
void dfs(TreeNode* root, string path) {
if (root == nullptr)
return;
path += to_string(root->val);
if (!root->left && !root->right) {
ans.push_back(path);
return;
}
path += "->";
dfs(root->left, path);
dfs(root->right, path);
}
vector<string> binaryTreePaths(TreeNode* root) {
dfs(root, "");
return ans;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
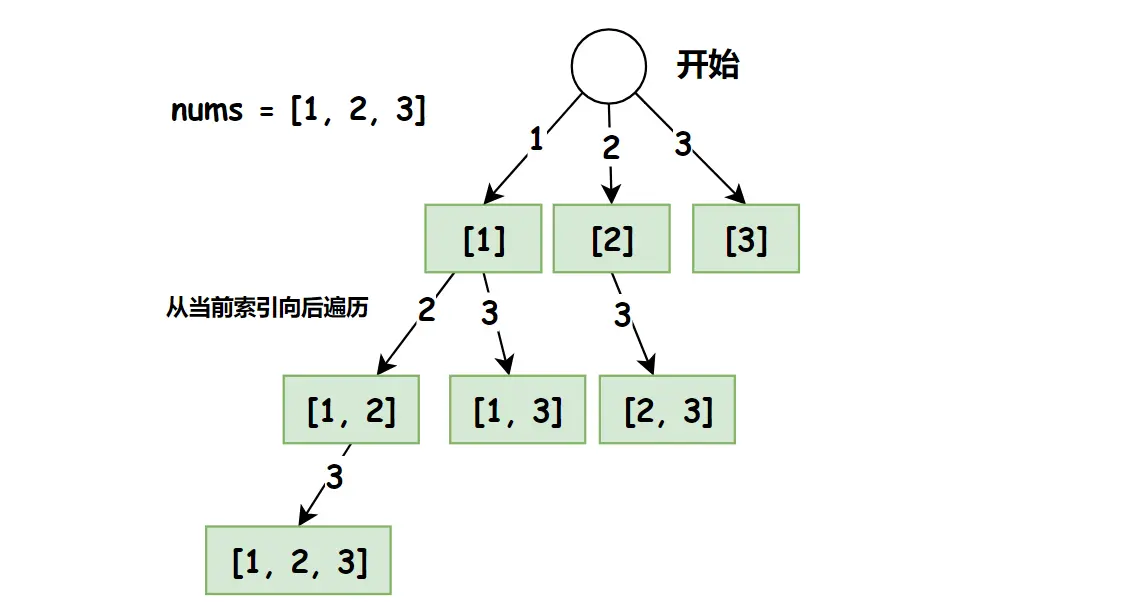
例题 2:78.子集 (opens new window)
给你一个整数数组 nums ,数组中的元素互不相同 。返回该数组所有可能的子集(幂集)。
- 画出决策树
- 思路转代码
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, int start) {
if (path.size() <= nums.size()) {
ans.push_back(path);
}
for (int i = start; i < nums.size(); ++i) {
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
int start = 0;
dfs(nums, start);
return ans;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
例题 3:全排列
给定一个不含重复数字的数组 nums ,返回其所有可能的全排列 。你可以按任意顺序返回答案。
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& check) {
if (path.size() == nums.size()) {
ans.push_back(path);
return;
}
for (int i = 0; i < nums.size(); ++i) {
if (check[i]) // 剪枝
continue;
path.push_back(nums[i]);
check[i] = true;
dfs(nums, check);
path.pop_back();
check[i] = false;
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<bool> check(nums.size(), false);
dfs(nums, check);
return ans;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 循环 vs 递归
循环和递归都是在处理重复的问题,二者可以相互转换,但是为什么有时候互相转换十分复杂?什么时候用循环?什么时候用递归?
循环适合处理线性的、单一路径的重复任务(如遍历数组或链表),因为它只需维护少数几个状态变量,无需“记忆”来路。递归则天然匹配树形或分治结构(如深度优先搜索),因为问题本身需要“回溯”——处理完子分支后要返回当前节点继续工作;递归利用系统调用栈隐式地保存了这些挂起的状态,代码清晰且符合直觉。虽然二者理论上可以相互转换,但将多路递归转换为循环时,必须手动模拟一个复杂的栈来保存所有待处理的分支信息。
# 综合练习
todo 从 P24~P29 未看,直接跳到了 29P,记于 26/4/12
# FloodFill 算法
洪水淹没算法:找一个性质相同的连通块,可以用 dfs 和 bfs 实现,推荐使用栈。
- 基于连通性:通常采用 4 连通(上下左右)或 8 连通(包括对角线)。
- 状态标记:访问过的点会被标记,避免重复处理。
- 终止条件:当邻域内没有符合条件的未标记点时结束。
class Solution {
public:
int dx[4] = {1, -1, 0, 0};
int dy[4] = {0, 0, 1, -1};
int ans = 0;
int m, n;
bool visit[301][301];
int numIslands(vector<vector<char>>& grid) {
m = grid.size();
n = grid[0].size();
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == '1' && !visit[i][j]) {
dfs(grid, i, j);
ans++;
}
}
}
return ans;
}
void dfs(vector<vector<char>>& grid, int x, int y) {
visit[x][y] = true;
for (int i = 0; i < 4; ++i) {
int c = x + dx[i], r = y + dy[i];
if (c >= 0 && c < m && r >= 0 && r < n && grid[c][r] != '0' &&
!visit[c][r])
dfs(grid, c, r);
}
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
todo 从 P35~P37 未看,直接跳到了 37P,记于 26/4/12
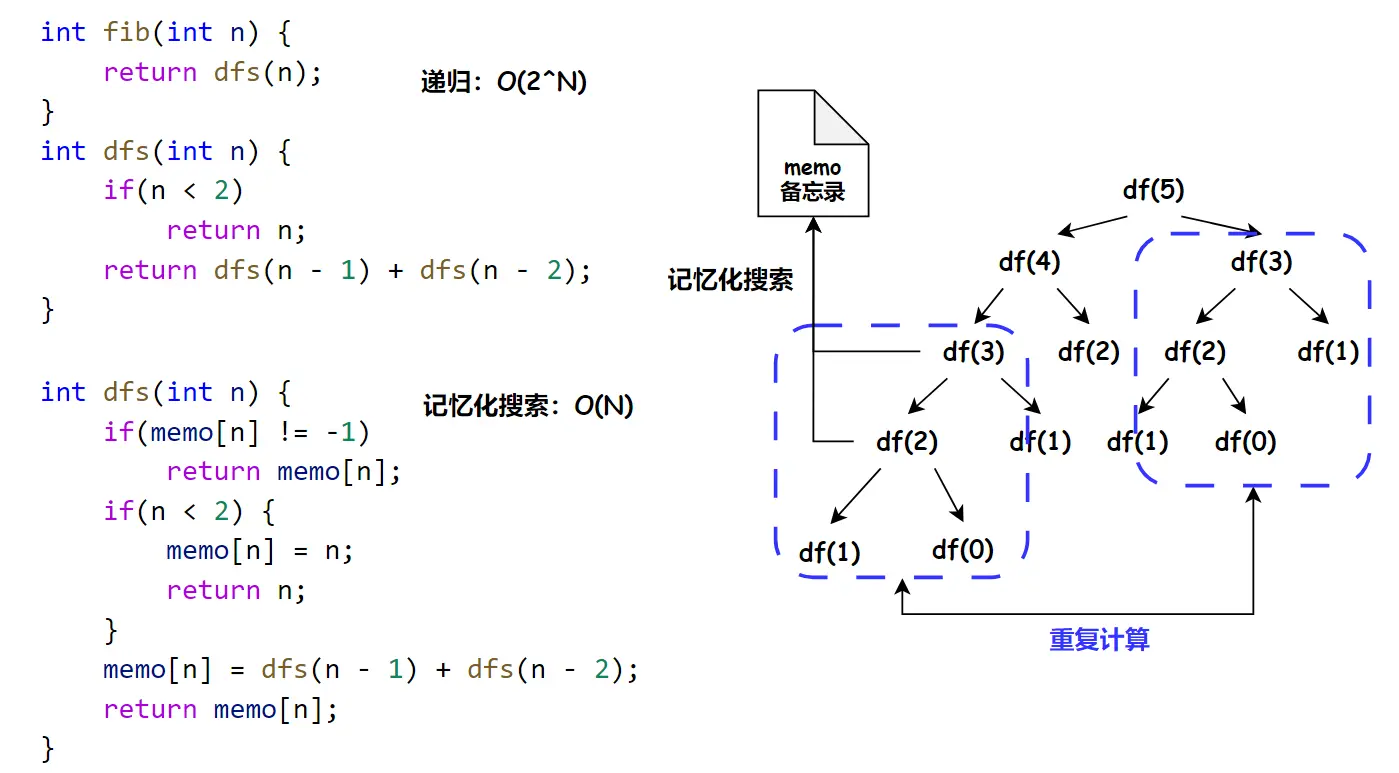
# 记忆化搜索
实现记忆化搜索的步骤:
- 添加备忘录 --> <可变参数,返回值>,初始化为不可能出现的值
- 每次递归返回时,将返回值放在备忘录中
- 每次进入递归时,在备忘录中查找一下
所有的递推都可以改为记忆化搜索吗?不是的,当递推过程中出现了大量完全相同的问题时,才可以使用记忆化搜索
暴搜 --> 记忆化搜索 = 动态规划
例如:斐波那契数,从暴搜到记忆化搜索:
# 宽度优先搜索
宽度优先搜索的过程中,每次都会从当前点向外扩展一层,所以会具有一个最短路的特性。因此,宽搜不仅能搜到所有的状态,而且还能找出起始状态距离某个状态的最小步数。但是,前提条件是每次扩展的代价都是 1,或者都是相同的数。宽搜常常被用于解决边权为 1 的最短路径问题,广泛用于树,无向图和二位数组中。
# BFS + 队列
BFS 是一种遍历/搜索策略:先访问离起点近的节点,再访问远的节点。队列是实现 BFS 的最自然的数据结构,因为它具有先进先出(FIFO)的特性,能保证“层”的顺序。
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
vector<vector<int>> ans;
queue<Node*> que;
que.push(root);
bfs(root, ans, que);
return ans;
}
void bfs(Node* root, vector<vector<int>>& ans, queue<Node*>& que) {
if(que.front() == nullptr)
return;
while (!que.empty()) {
int n = que.size();
vector<int> level;
for (int i = 0; i < n; ++i) {
level.push_back(que.front()->val);
for (int j = 0; j < que.front()->children.size(); ++j) {
que.push(que.front()->children[j]);
}
que.pop();
}
ans.push_back(level);
}
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 单源最短路问题
用 BFS 求无权图(边权为 1,即两个节点之间边的长度为 1)的最短路径的核心原理:
- 适用条件:所有边的权值都相同(通常就是 1),BFS 就能用来求最短路径。
- 方法:从起点开始做一次 BFS。
- 如何得出最短路径长度:BFS 扩展的层数就是最短路径的长度。
此外,使用队列,用来控制顺序,存储接下来要访问的节点,保证先进先出(FIFO);数组或者哈希表用来避免重复,记录哪些节点已经访问过。
1926.迷宫中离入口最近的出口 (opens new window)
class Solution {
public:
int dx[4] = {1, -1, 0, 0};
int dy[4] = {0, 0, 1, -1};
int nearestExit(vector<vector<char>>& maze, vector<int>& entrance) {
int m = maze.size(), n = maze[0].size();
queue<vector<int>> que;
vector<vector<bool>> visit(m, vector<bool>(n, false));
que.push(entrance);
visit[entrance[0]][entrance[1]] = true;
int ans = 0;
while (!que.empty()) {
ans++; // 每扩展一层,ans++
int size = que.size();
for (int i = 0; i < size; ++i) {
vector<int> cur = que.front();
que.pop();
int x = cur[0], y = cur[1];
// 四个方向遍历:
for (int j = 0; j < 4; ++j) {
int nx = x + dx[j], ny = y + dy[j];
if (nx >= 0 && nx < m && ny >= 0 && ny < n &&
maze[nx][ny] == '.' && !visit[nx][ny]) {
// 在边缘:
if (nx == 0 || nx == m - 1 || ny == 0 || ny == n - 1) {
return ans;
} else {
visit[nx][ny] = true;
que.push({nx, ny});
}
}
}
}
}
return -1;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 多源最短路问题
多源最短路问题就是有多个起点(源点),求每个点到所有起点的最短距离,或者到任意起点的最短距离。
边权为 1 的多源最短路问题可以用多源 BFS 来解决。思路就是把所有的源点当作一个“超级源点”,将问题转换为单源最短路问题,代码层面就是把所有的起点放在队列中一层一层往外扩展。
class Solution {
public:
vector<vector<int>> updateMatrix(vector<vector<int>>& mat) {
int dx[4] = {1, -1, 0, 0};
int dy[4] = {0, 0, 1, -1};
int m = mat.size(), n = mat[0].size();
vector<vector<int>> ans(m, vector<int>(n, 0));
queue<pair<int, int>> que;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (mat[i][j] == 0) {
que.push({i, j});
} else {
mat[i][j] = -1;
}
}
}
while (!que.empty()) {
auto cur = que.front();
int x = cur.first, y = cur.second;
que.pop();
for (int i = 0; i < 4; ++i) {
int nx = x + dx[i], ny = y + dy[i];
if (nx >= 0 && nx < m && ny >= 0 && ny < n) {
if (mat[nx][ny] == -1) {
ans[nx][ny] = ans[x][y] + 1;
mat[nx][ny] = 0;
que.push({nx, ny});
}
}
}
}
return ans;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 拓扑排序
- 基础概念
- 拓扑排序针对有向无环图(DAG),涉及顶点的入度和出度。
- AOV 网(顶点活动图):用顶点表示活动、有向边表示活动先后顺序的图结构。
- 拓扑排序
拓扑排序是将 DAG 的所有顶点排成一个线性序列,这个序列就是完成所有活动的一个合法顺序,排序结果可能不唯一。
- 如何排序
- 找出当前图中入度为 0 的顶点,输出它(或记录到结果序列中)。
- 从图中删除该顶点,并删除从它出发的所有有向边(即让这些边的终点的入度减 1)。
- 重复步骤 1 和 2,直到图中没有顶点为止。
- 如果图中还有顶点,但找不到入度为 0 的顶点,说明图中存在有向环,无法完成拓扑排序。
- 如何实现
- 初始化:计算每个顶点的入度,创建一个空队列,将所有入度为 0 的顶点加入队列。
- 循环处理(BFS):当队列不为空时,重复以下操作:从队列头部取出一个顶点 u,将 u 加入结果列表,遍历 u 的所有出边 u → v:将顶点 v 的入度减 1(相当于删除边 u→v)。如果 v 的入度变为 0,此时将 v 加入队列尾部。
- 结束检查:循环结束后,检查结果列表的长度:若长度等于图中的顶点总数,说明所有顶点都被成功排序,图无环;若长度小于顶点总数,说明图中存在环,无法完成拓扑排序。